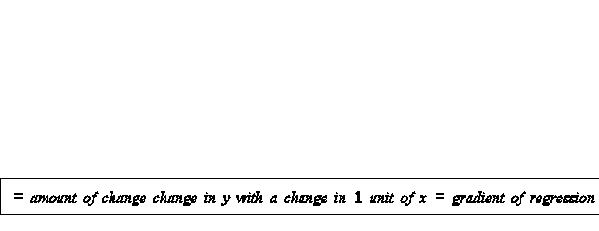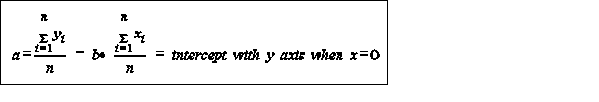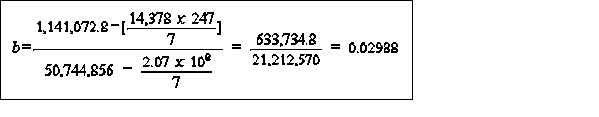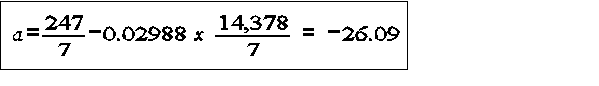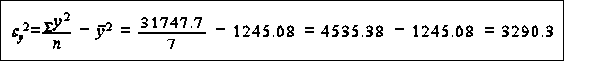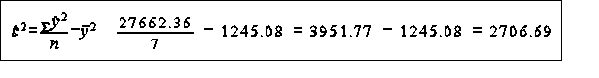
|
|
|
|
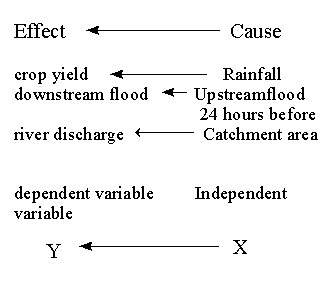
Bivariate regression the correlation coefficient measures the association between 2 sets of paired variates, but it does not 1) tell us the way the two variables are related 2) does not allow us to predict the value of one variable with knowledge of the value of the other variable 3) doesn’t signal anomalies in the relationship between individual pairs bivariate regression lets us do all of these things dependent and independent variables regression allows us to suggest (hypothesize) causal relationships and their direction - substantiated by previous research and common sense
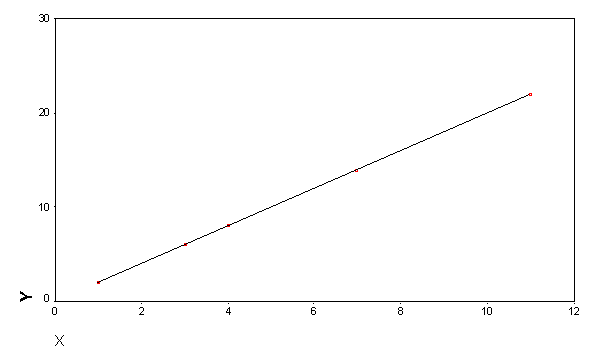
scattergram - used to plot dependent along y axis, independent along x axis regression involves plotting a ‘best-fit’ line between the points on a scattergram convention is to treat the dependent variable as PREDICTED and the independent variable as the PREDICTOR prediction/interpolation is one of the main uses because x and y are sampled. As we don’t have complete information on values for a given x we want to interpolate intermediate values from the best fit line on the scattergram derivation of best fit line example 1:
easy to place ‘best’ line through these points as the association is perfect correlation coefficient =1 there are no residuals/anomalies/no deviations of points from general relationship since every point is on the regression line however variables are rarely perfectly correlated because of 1) poor/theory/understanding or 2) measurement error
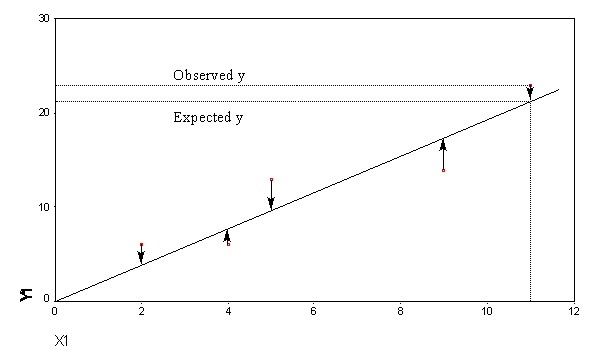
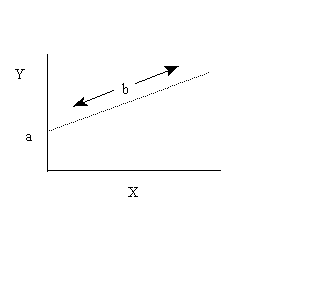
example 2 can place ‘best-fit’ line through points although r<1 and so points representing variates do form a straight line deviations/anomalies/residuals from regression are shown as 89residuals: why plot them vertically rather than perpendicular to the regression line? Because residuals are the difference between the actual/observed values of the dependent variable (y values) and the expected/predicted value of the dependent variable ( y hat ) for a particular value of xfitting the regression line by least square method any straight line drawn on an x y coordinate system can be represented by an equation of the form
least square- objective to find the combination of a,b values which minimize the sum of squares of the residual values, that is, minimize the difference between the actual and predicted values at particular values of x
example
the standard method of measuring the goodness of fit of a regression is to calculate the extent to which the regression accounts for the variation in the observed values of the dependent variable this is done by calculating the variance of the observed value of y
tests on the residuals a complementary test of goodness of fit involves looking at the residuals there should be no systematic variation in the residuals example of coefficient of determination
|