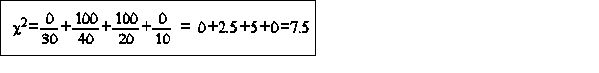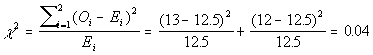
|
|
|
|
Chi-square test (P2) nominal data (categories) one-sample, two-sample, > 2 sample test research question: are wheat growing farms located with respect to soil type? That is, is wheat grown in particular soil-type areas? 1) take a random sample of 100 wheat farms and determine the soil types underlying the farms 2) there are 4 ‘classes’ of soil type
this is the ‘observed’ distribution of wheat farms 3) under a null hypothesis what would be our ‘expected’ distribution? Answer: the % percentages of land under different soil types
our null hypothesis is that: H0: soil type has no influence on wheat farm location if H0 was true, then we would expect the observed number of wheat farms to be roughly equal to/proportional to actual % of land under particular soil types
what we found was
are these differences significant or could they have occurred due to random sampling differences? DO SAMPLING DIFFERENCES REFLECT DIFFERENCES IN POPULATION OVER SOIL TYPE 4) H1: Soil type has an influence on wheat farm location 5) Set significance level at 95% confidence or "=0.05
6) compute P2 statisticwhere Oi = observed value in category I Ei= expected value in category I k= number of categories
look up critical value (pg 276 in text) df= k-1=4-1 = 3 df - means that given the total frequency, once the frequencies are known for all but one of the categories, the frequency in the final category is determined P 2 c("=0.05) (df=3) = 7.815if Oi and Ei were equal then P2 =0P 2 > as differences >7.815 defines value of P2 where top 5% distribution starts with df=3in this case P2=7.5To reject H0: calculated value must exceed the critical value we cannot reject H0: cannot say that we would expect the value 7.5 to occur $ 95 out of 100if H0 is correct, the probability of 7.5 occurring is > "=0.05therefore farming is not related to soil type
rules of thumb 1) if the number of categories is greater than 2, no more than 1/5 of the expected frequencies should be less than 5 and none should be 0 2) if the number of categories is 2, both the expected and observed frequencies should be 5 or larger these illustrate an important restriction on P2 in that for many categories there should not be small frequenciesalso the data must be in frequencies, P2 will give false results if used on proportions or percentages of occurances in categoriespoisson example We begin our discussion by querying: Does the following sequence of data "fit" the Poisson distribution?
The null and alternative hypotheses:
The test statistic and sampling distribution: we select the test statistic and distribution currently under discussion. That is,
with df=n-k-1 where the expected (denoted as Ei) and observed (denoted as Oi) are determined via a frequency distribution and k is the number of parameters which require estimation before the test can be conducted, and n is the number of intervals over which the frequency distribution is determined. To complete the required test, we must first determine some overall attributes of the data set. As we can see the data values ranges from 2 to 10.
Then we must determine a reasonable breakdown of this range to use as the basis of our test. We first do a frequency analysis.
Notice the check down at the lower right corner to make sure that my frequency analysis "read" all of the observations. Then we "compress" this breakdown a little to make sure we have more than 5 observations per interval.
computation of the test statistics
Further the degrees-of-freedom is determined to be n - k - 1 = 6 - 1 - 1 = 4, i.e., n = 6 intervals, k = 1 parameter required computation before the test could be run. Draw a conclusion The quantity in green is the p-value our P˛ = 7.290. This is the probability of randomly being more extreme than 7.290 in the P˛ with 4 degrees-of-freedom. Since this p-value = 0.2202 is larger than 0.05 we cannot reject the null hypothesis in favor of the alternative. If we consult the tables in the text we find that the critical P˛ (for = 0.05) to be 9.488. P˛ and the fit to a poisson distribution Some statistical points to note about the Poisson distribution Like the binomial distribution it is assumed that events are independent of one another. : is generally unknown and must be estimated by a sample mean.
Testing a spatial (and temporal) distributionOften we wish to discover if spatial and temporal patterns are random. If they are not then a pattern must be regular or clumped (aggregated), in which case there is probably an interesting biological process at work. As an example let us assume that we are interested in the spatial arrangement
of buzzard Buteo buteo nests. We could set up two hypotheses: Ho : Buzzard nests are randomly distributed H1 : Buzzard nests are not randomly distributed We could test the Ho by collecting data from a number of 4km˛ squares. In each square we record the number of nests. (The size of the square is determined with respect to the biology of the organism) The results are tabulated in a frequency table. In this example 60 squares were assessed.
Average number of nests per square = 120 / 60 = 2.00 (the sample mean x) the mean of the sample (x), is our best estimate Substituting this value into the Poisson equation enables us to calculate the
probability of observing 0, 1, 2 etc. nests per square. The steps are
summarized below. Assume that nests are randomly distributed with a mean of 2.00 nests per square.
Use the Poisson equation to find P(0), P(1), P(2) etc., nests per square. Convert these probabilities to expected numbers of squares by multiplying the probabilities by the number of surveyed squares. For example, suppose that P(1) = 0.25 (25% chance of finding 1 nest per square) we would then expect to find that 25% of the surveyed squares would contain one nest as long as the number of nests per square was random with a mean of 2.00 nests per square. In this case 60 x 0.25 = 15. Results
Note that the simplest way of finding P(5+), if not using tables, is by
subtraction, ie 1 - 0.9474, where 0.9474 is 0.1353 + 0.2707 +0.2707 + 0.1804 +
0.0902. In order to determine if the nests are randomly distributed we need to find out if the differences between what we observed and what we would expect, given a random distribution, are significant. If these differences are significant we can conclude that the pattern of buzzard nests is not random. It is also possible that the pattern could be random and any differences between observed and expected frequencies may have arisen by chance. In order to decide between these alternatives we must use a statistical test which allows us to compare the observed and expected frequencies and determine if there is a significant difference between these two sets of frequencies. The intermediate calculations needed for this test are shown below
Using the data above P˛ = 2.09 + 2.04 + 0.09 + 0.06 + 0.46 + 0.42 = 5.181. Normally this would be the end of our calculation of P˛ , but there is a common complication. Because of a bias that it introduces, we should not use expected frequencies < 5 in the calculation of P˛ . When they occur they should be amalgamated with the next value (above or below as appropriate). In this example, 3.16 (E(5+)) is added to 5.41 (E(4)) to give 8.57 (E(4+)). Since we have combined the expected frequencies we must also combine the observed, i.e. 7 + 2 = 9. Using this correction
Our value, 4.31, is smaller than 7.815 consequently we fail to reject Ho and say that the distribution of nests is not significantly different from a random distribution with a mean of 2.00.
One problem with this approach is that it is very dependent on the scale of the study. If we had worked with 1km˛ squares we would probably have come to a different conclusion. Scale effects are an important topic in all spatial analyses. the material for the poisson example is derived from http://149.170.199.144/resdesgn/poisson.htm Chi squared and the normal distribution
Does the following data set accurately "fit" the normal distribution with a mean of 0 and a standard deviation of 1?
This naturally induces the following hypothesis testing steps: 1) The null and alternative hypotheses: H0: The sample is drawn from a population distributed as N[0,1] HA: Not. 2) Select the test statistic and sampling distribution:
The first step in this process is to reorder the data in increasing order, i.e., as in the next table:
From these data one can begin to develop potential candidates for partitioning the range of both the observed and the expected frequency distributions. The intervals listed in the following table represents a reasonable first pass at such a partition.
The process of developing partitions illustrates one of the most significant limitations concerning the use of the P˛ goodness-of-fit tests.The use of any nonparametric tests is critically dependent upon the number of data points, and the assumptions of the P˛ goodness-of-fit test are: All expected frequencies are at least 1. At most 20% of the expected frequencies are less than 5. We are casual in our respecification of our intervals, compressing the interval specification depicted in the table above to the version presented here:
Next we are required to determine the expected frequency of each interval in this partition. further computation yields the following results:
A note for clarification is in order at this point. The rule specifying that the frequency must be greater than or equal to 5 causes some problems at this point. Clearly, in the above example, 2 of the expected frequencies are less than 5. Since the sizes or number of intervals within a partition is at the analysts` discretion, these intervals must be combined further, as indicated below:
But the difficulty here is that now our test statistic is incredibly small, i.e.,
Given our discretion on the interval specification, we compromise to determine the following:
Given this information, we then can --- 3) Determine the rejection region: We needed to know the specifics of the interval structure that we were going to use for our test since we needed to know the degrees-of-freedom for determining our rejection and non-rejection region. In this example n = 4 and k = 0, so n - k - 1 = 4 - 0 - 1 = 3. Reject if: P2 7.8154 Compute the test statistic value:
= 1.676 + 1.575 + .788 + 1.676 = 5.715 5 Draw a conclusion: The data do not support the rejection of the null hypothesis that the data set is drawn from the standard normal distribution.
Normal distribution example taken from:www.som.clarkson.edu/~cmosier/simulation/Random_Numbers/Testing/Chi_Squared_gof/chi_gof.html Degrees of freedom and P2 the degrees of freedom for the P2 test is n-k-1 where n is the number of classes, k is the number of restrictions in addition to the one imposed by the table total or the mean the textbook shows it as n-r but you will always have to lose 1 degree of freedom because you will know the table total or mean so its an equivalent formula in most situations k=0 so df=n-1 but when using P2 for goodness of fit k may take on other values in using the Poisson distribution k=1 for a normal distribution k=1 because of the mean and the variance but if the data is already in standardized form as in the example k=0 if P2 is being used as a test for independence in a contingency table df=(r-1)(c-1) where r is the number of rows and c is the number of columns | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||