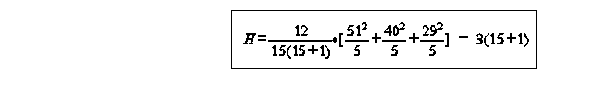
|
|
|
|
Kruskal-Wallis test more than 2 sample tests, test if means of k samples are drawn from different populations K-W 2 equivalent of parametric F-test (1 way ANOVA)no need to meet all the assumptions of parametric test (is distribution free ANOVA by ranks) simple, good for small samples, powerful K-W for strong ordinal (ranked) data example 1: for up to 3 samples, 5 values each if there are more than 5 values per sample it’s distributed as a P2 with df = k-1calculate H statistic, can get an exact probability that samples are from the same population samples from the population of Canadians, which of the following list of 15 cities would you prefer to live in? Separate results in western, central and maritime cities {note the rankings are of the overall sample, not the rankings within the samples]
STEP 1: set up hypothesis H0: no difference in terms of residence preferences between the 3 groups of Canadian cities- observed differences due to chance variations in response H1: residence preferences are significantly related to location, preference differences are so great that they are unlikely to have arisen by chance level of rejection at "=0.05, 95% confidence not by chancestep 2: calculate H define: j=sample, j=1...k k=number of samples rj=sum of ranks in jth sample nj=number of ranks in jth sample n= Gnj - sum of individuals in samplesif there are tied ranks use the mean of ranks of values they would have otherwise received
step 3: look up critical value (Pg 281 in text) critical H, n1=5,n2=5,n3=5, k=3, "=0.05=5.78computed H must be $ critical value to reject H0since 2.42 < 5.78 we cannot reject H0 large samples sampling distributions for cases where all the sample >5, is similar to that of P2 with df=k-1, where is the number of samplescorrection for tied rankings
Ti=ti3-ti with ti being the number of tied observations in the ith group of scores, m=number of ties t is the number of individuals involved in each set of tied ranks the effect of the correction is quite small the effect is to make the value of H larger and so increase the chance of rejecting the null hypothesis so if the correction is ignored you are erring on the side of caution unless more than 1/4 of the values in the data set produce tied ranks, the effect of the correction is negligible | |||||||||||||||||||||||||||||||||