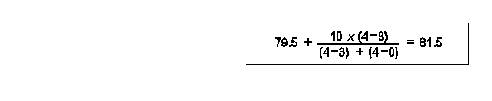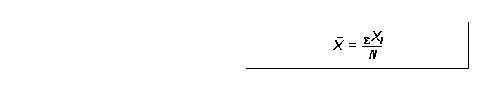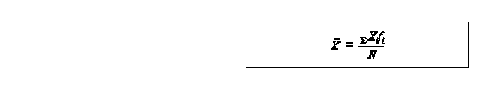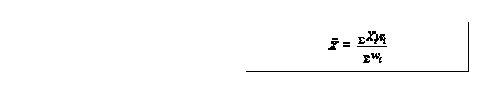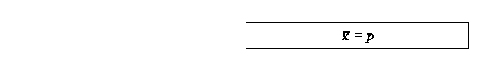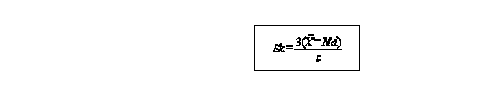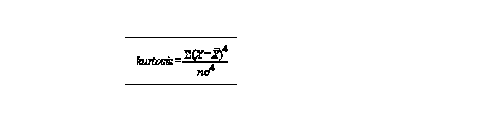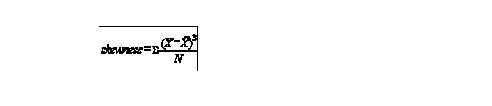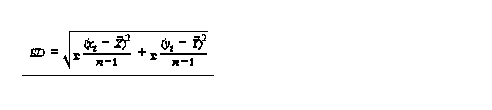
|
|
|
|
criteria for measures of centre & spread 1) appropriate for the measurement level of the variable 2) "rigidly defined rather than just approximated 3) based on all observations 4) simple & comprehensible 5) calculated with ease 6) expressed in algebraic terms 7) robust (little affected by fluctuations between samples) possible other criteria 8) unique, rather than multivalue 9) generalizable to 2 or more variables 10) resistant to outliers 11) not overly affected by combining categories 12) defined even when variable has open ended categories 13) equal to actual data values, or at least in their metrics if using samples 14) consistent for large samples 15) unbiased for small samples 16) efficient when compared to other possible estimators levels of measurement measurement - the process of assigning labels or values to observations can divide variables into a couple of basic types 1) nominal - a series of unordered categories its the lowest level i.e. regions we can examine the distribution each category is listed with its corresponding frequency total number of cases is N can show the proportion of different categories can also be represented as a percentage distribution percentages are just proportions multiplied by 100 example
Immigration into US by Last residence 1820-1988 in thousands Ordinal scales some nonnumeric variables have order to their categories these are called ordinal variables a prevalent type of ordinal data is ranked data in dealing with ordinal data one can use the percentile a percentile is a category of the variable below which a particular percentage of the observations fall weak ordinal - where one can identify 'more than', 'less than' quality to 2 or more categories strong ordinal - stronger ranking - but where exact quantitative difference between pairs of ranked items is unknown, i.e. a preference scale of preferred cities metric scales - a variable that has a unit of measurement, ie. inches it answers the questions of how much or how many 2 major types: ratio and interval ratio - is numeric with defined unit of measurement and a real zero point because there is a zero point one can make ratio statements such as statement that one person is twice as tall as another interval - defined unit of measurement but no real zero point i.e. temperature dichotomous variables - binary variables, very common in social science, it is nominal categorization rules 1) mutually exclusive 2) mutually exhaustive measures of centre 1) mode - simplest indicates which category is most common main advantage is that its easy to compute 4 problems a) may not be very descriptive b) distribution may be bimodal or multimodal c) can be overly affected by sampling variation d) very sensitive to how categories are combined when dealing with grouped metric data there is a) crude mode = midpoint of most frequent interval b) refined mode = L = lower limit of the modal interval, w width of the class interval, fmo = frequency of the modal interval, f b the frequency of the interval below the modal interval, fa = frequency of the interval above the modal interval
example temp frequency 65-69 2 70-79 3 80-89 4 N = 9 mode = 80-89 crude mode 84.5 refined mode 81.5 example
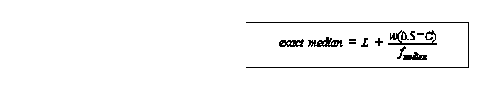
median for ordinal data = category of middle case not meaningful to take averages of ordinal data formula is median = category of the (N+1)/2th case median for metric data Xmedian = value of X for the (N+1)/2th ordered case for odd N = [average of N/2th and (n/2)+1)]th ordered case for even N advantages 1) not affected by extreme values 2) can sometimes be computed even if distribution is open on both ends median for grouped metric data rough median = midpoint of class containing middle case exact median= L = lower limit of the class containing the 50th percentile, fmedian = freq of class containing 50th percentile, w = width of the interval of 50th percentile, C = cumulative freq below the 50th percentile class
mean for metric data
2 important properties 1) sum of deviations from the mean = 0 2) sum of + deviations = sum of - deviations 2 advantages 1) more stable than other measures 2) other important statistics can be derived using it i.e variance and SD problems a) fractional values b) cannot be computed if data is openended c) strongly affected by extreme cases mean for grouped data
the weighted mean
wi= weight associated with ith case weights compensate for the higher chances of selecting some cases than others example is if pooled mean is of interest, values should be weighted by number of cases that made up each mean mean for dichotomous data
where p is the proportion of successes or cases coded 1
these measures of central tendency tell us nothing about the variability in the data or the dispersion one way to do this is compare the values with the mean value the simplest way is to subtract the mean from each value to see if it is higher or lower if you do this you get both + and - values if we summed them to get a sort of index we would get 0 as a total, to get around this we square the differences |Xi- 0| this known as the sum of squaresor the total squared variation about the mean from this we can derive the variance and the standard deviation variance is the sum of the squared deviations from the mean divided by N for the population and n-1 for a sample remember that sample statistics are estimates of the population statistics the sample uses n-1 because it has been shown that the use of N for a sample results in an underestimation of the population variance
a short cut formula for the sample variance is
standard deviation s = %s2a large standard deviation means a large variability in the data
variance can also be calculated for grouped data
where fi=frequency of classes M=grouped mean empirical rule: if distribution is approximately then mean + 1sd 68% of distribution Mean +2sd 95% of distribution mean +3sd 99.7% of distribution example A B FOR a 'Xi=3+7+9+2+4+6=313 30 'X2 = 32+72+92+22+42+62=1957 70 ( 'Xi)2= 312=9619 90 2 20 x=31/6=5.164 40 6 60 s2=6(195)-961/6(6-1)=6.96 s=2.639 for b x = 51.6 s2=696.6 s=26.39 coefficient of variation - problem with variance and sd is that for the purpose of comparison, they are sensitive to the magnitude of the data
for example in the previous data the variance and sd of b was 10 times that of a to compare a and b we need to standardize coefficient of variation (cv) = s/x bar =std dev /mean of x for a and b the cv is 2.639/5.155 = .51 or 26.39/51.6=.51 example application measure the cv for different time periods for per capita income for pop research question is: is the variation in income levels increasing or decreasing for US 1880:.321, 1920:.291, 1940:.263, 1960:.176 variance is decreasing skewness and kurtosis previous measures don't provide any info about the shape of the distribution
another alternative is Pearson's coefficient of skewness that takes into account the position of the mean and median a positive sign indicates a right (positive skew) a negative sign indicates a left of negative skew
as long as its within + or - 3 it can be considered moderate there are alternative measures for skewness and kurtosis
these last 2 are used for $ indiceslike variance, skewness and kurtosis are an absolute quantity that is their values are affected by the magnitude of the data to compare distributions we need relative measures
curve with $2 > 3 are leptokutic - highest freq in a few classescurve with $2 < 3 are platykurtic - freq in all classes nearly identicalcurve with $2 = 3 are mesokurtic - normaldistribution statistics for spatial distributions the bivariate mean in geography the centre of an area may be of interest, can calculate the weighted bi-variate mean centre or the weighted centroid
standard distance dispersion has it counterpart in bivariate descriptive statistics because distances are deviations in the geographic sense, it is defined as the equivalent of a standard deviation
if you want to take possibility of an ellipse rather than a circle then we can calculate standard distance separately for X and Y
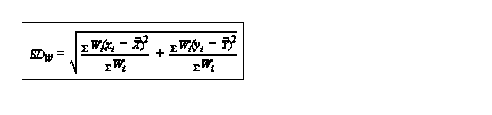
for weighted observations
this is far too tedious to do by hand so we would have to write a program to do it |