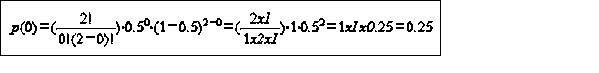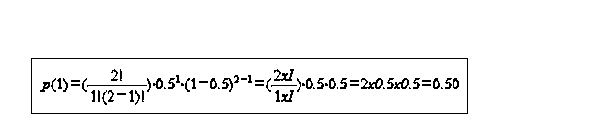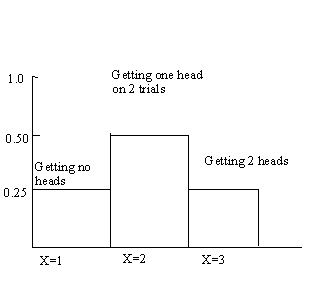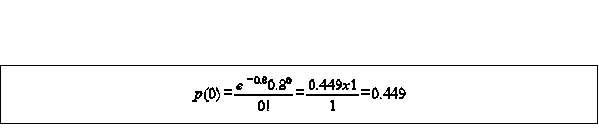



|
|
|
|
probability distributions a probability distribution is a set of probabilities of all possible events in a given situation e.g. situation = rolling die all possible outcomes = 1,2,3,4,5,6 probability distribution is the set of all possibilities associated with the set of events prob distribution Y p(1) = p(2) = p(3) = p(4) = p(5) = p(6) = 1/6 = 0.1666graphically
a probability function is a mathematical description of the probability distribution prob. funct. Y p(x), x=event = 1/6discrete probability functions - where there are finite # of outcomes such as above, others are binomial and poisson distributions continuous probability functions - where there are infinite # of outcomes e.g.. inches of rainfall, probability of any one value =0 use of probability functions they act as benchmarks with which judge the strangeness of a particular event i.e. how unusual or unlikely is it
expected value of a random variable
suppose we toss 3 coins repeatedly what would be the average number of heads per toss? Looking at figure we see 0 heads 1/8 of the time, 1 head 3/8 of the time, 2 heads 3/8 of the time, and 3 heads 1/8 of the time
in the long run we would expect the average number of heads per toss of the 3 coins to be E(X) = 0(1/8) + 1(3/8) + 2(3/8) + 3(1/8) = 12/8 = 1.5 Expected value is then E(X) = x1p1 + x2p2 + .... + xmpm the expected value is not necessarily expected to actually occur in a trial, ie 1.5 heads example What is the expected value (long run average) of the number of dots facing up for the roll of a single die? Our sample space is (1,2,3,4,5,6) the probability distribution is then
E(X)= 1(1/6) + 2(1/6) + 3(1/6) + 4(1/6) + 5(1/6) + 6(1/6) = 21/6 = 3.5
different probability distributions exist for different situations
the binomial distribution
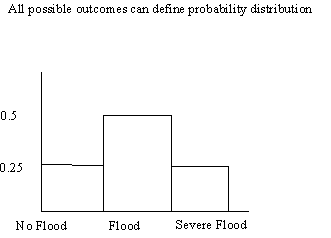
1) there are a fixed number of trials (#of coin tosses) (#of years) 2) each trial has only two possible outcomes (H/T) (flood/no flood) 3) probability of getting a success on any one trial is the same for all trials (e.g. sampling with replacement) (flood/no flood) 4) the trials are independent (one does not affect another)
p(x) = probability of event x next term - combinations formula B x= probability of success of one trial(1- Bn-x)= probability of failure of any one trialE(X)=EnB var=nB(1-B) probability of event x given n trials = #of ways it can occur times expected probability of occurrence times expected probability of not occurring e.g. toss of a coin: what is the probability of getting 0,1,2 heads on 2 coin tosses (2 trials) 1) # of trials is fixed n=#of trials = 2 2) each trial has two possible outcomes (heads/tails) 3) probability of heads on 1st,2nd or 3rd trial is the same 4) trials are independent events where n trials = 2
1st term = take 2 objects, one at a time HT,TH 2 trials one after another the 2 in 2x0.5x0.5 comes from fact that combination can occur twice (HT,TH) this is the probability distribution for example problem, the set of all possible events in this situation
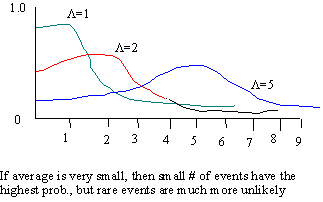
The binomial distribution can be used to determine probabilities of success for binary variables subjected to a number of trials. However, if n, the number of trials, is large and/or p or q is small the calculation of the binomial probabilities becomes impracticable because nCr becomes too large or pr becomes too small for sensible computation. Fortunately the binomial distribution is linked to two other probability distributions. As n becomes large, and p and q are sufficiently larger than 0 ( i.e. >1/n) the binomial distribution tends towards the normal distribution. But, when n becomes large and p or q approach 0 ( i.e. one of them is < 1/n ) the binomial approaches the Poisson distribution. For example, we could make use of the Poisson distribution if we had a population of 100 (n) and the probability of dying (p) was 0.001. 0.001 is 1/1000 which is less than 1/n (1/100 or 0.01). poisson distribution often used to describe phenomena that have a low probability of occurrence, ie. e events that occur very infrequently or rare e.g. # of cars using 401 highway, what is the probability of a very large traffic flow occurring that would block the highway e.g. # of fire calls in London, what is the prob. of a large # of fires occurring and there not being enough engines to answer all the calls? e.g small earthquakes are common but large ones are not, what is the likelihood of an 8.0 earthquake in the next 10 years in S. California answers these questions, what is the prob. of a certain number of random independent events occurring given that we know the mean number of events occurring binomial- when we use this distribution we specify the number of trials and we know the probability of success on any one trial. but if we don't know the number of trials, or the probability of success we use poisson Distribution is used to model the occurrence of rare events within set time period. 1)used as an alternative to the Binomial distribution in the case of very large samples. For the Poisson you do not need to give a sample size. If the sample size is known, it is generally preferable to use the Binomial. main differences between the Poisson and the binomial distribution is that in the binomial all eligible phenomena are studied, whereas in the Poisson only the cases with a particular outcome are studied. Ie in the binomial all cars are studied to see whether they have had an accident or not, whereas in the Poisson only the cars which have had an accidents are studied. 2) The Poisson can also be used to study how 'accidents' or 'malfunctions' or the chance of winning the lottery never, once or more than once, are distributed on the level of a population. If having one 'accident' has no influence on the chance of having another accident, the victim is 'put back into the population' immediately after an 'event', people may have one, two, three, or more accidents during a certain period of time. One assumption in this application of the Poisson is that the chance of having an accident is randomly distributed: every individual has an equal chance. Mathematically this is expressed in the fact that the variance and the mean for the Poisson are equal. A good way to check if this assumption that individuals have an equal chance of having the trait is correct, is to compare the variance of an (accident) distribution with its mean. If the variance is larger, then the assumption was not correct. Criteria for use: 1) The number of events in any time period or area is independent of the events in another period. 2) The probability that one event occurs within a time period or area is low and the probability of multiple events is very low. 3) The time periods are small compared to the longer interval of observation. all we need to know is the average number of occurrences to estimate prob. of a certain number of events occurring
where x=# of events e= base of natural log = 2.71828 8 =mean # of occurrencese.g.. in a 65 year period there have been only 99 days in which rainfall has exceeded 30 mm in a day 8 =mean # of occurrences in a year = #of days it has occurred/#of years = 99/65=1.523so on average we get 1.5 days where rainfall exceeds 30 mm, a rare event what is the prob. of the event occuring 5 times in a year so this event will occur only 15 times in a thousand years in a 65 year span 0.015x65=0.975 about once every 65 years
most widely used cases in geography are for point pattern analysis poisson also used to describe distributions of objects that may or may not be random eg. distribution of trees affected by acid rain - is this distribution random or isn't it? if not then some spatial process is occurring the probability of any one pattern is very low. number of trees affected =20 # of quadrants = 25 the mean # of trees per quadrant=0.8= 20/25 probs of quadrants containing 0,1,2,3,4 of these affected trees are
we could do a stat test but it appears to be a good fit so trees are randomly distributed
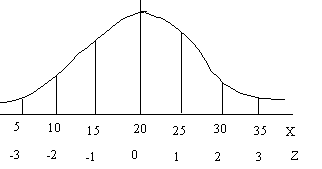
normal distribution the most used statistical distribution. The principal reasons are: 1) Normality arises naturally in many physical, biological, and social measurement situations. 2) Normality is important in statistical inference. Properties Bell shaped curve. Mean, median and mode equal and located at the center of the distribution. Only has one mode. Symmetric about mean. Continuous Never touches x-axis. Area under curve equals one. (Probability of something happening is a continuous distribution - a probability density function where the probability that any particular value will occur = 1/ 4values close to the mean are more likely to occur than values farther away from the mean [draw graph of distribution] the p.d.f.(x) depends on the values of 2 parameters
1) B, the mean of x2) Fx, the standard deviation of x1 and 2 combinations are infinite so we cannot generate probability tables to allow for different combinations of 1 and 2 you can transform values of x to standardized values called z values z = the # of standard deviations from the mean
we can generate probability tables associated with z values
area under the curve = Eprob. =1
50% of the cases are to the left and right of the mean
uses 1) what is the probability of a Canadian having a income between 10k and 15k? since the curve is symmetric, this is the same as getting value between 1 and 2 std of the mean answer: prob of z=0 to z=2 = 0.4772 prob of z=0 to z=1= 0.3413 therefore area under the curve from z=1 to z=2 = 0.4772-0.3413=0.1359 so there is about an 14% chance 2) uses in significance testing in above example would a value of 35 be significantly different from the mean of 20 eg let x=levels of lead in drinking water eg. p.p.m. (a) set up 'null hypothesis' H0: a value of 35ppm is not significantly different from the mean (b) set up the significance level - we want to be 95% sure of our conclusion concerning H0: so "=0.05from z=0 to z=±1.96 = 95% of the curve " =0.05 = prob of lying in a region of rejection of H0:1- " = prob. of lying in region of acceptance of H0:
therefore if prob. associated with value of 35 is <0.025 then we can conclude that with 95% certainty, it is significantly different from the mean of 20 what is the prob. of 35? z=3=35-20/5 we know=0 to 3 is .49865 so prob of being $35 = 0.5-.49865=0.00135which < 0.025 so 35 is significantly different from 20 the above is called a 'two-tailed test' where the question is is the value significantly different from the mean (no direction specified) could perform a one-tailed test where you specify direction i.e. is 35 significantly larger than the mean are we say 95% certain its larger, now all the %% error is in the tail so we are more likely to reject H0 some researchers question the validity of 1-tailed tests since they are more liberal it is possible to accept H0 that a value is significantly larger but reject that it is different when in doubt use the 2 tailed test type I error: rejecting H0 when it is true, this is minimized by using small values of "type II error: accepting H0 when it is false minimized by choosing large values of " i.e. .10
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||